长安十二时辰的大案牍术是如何做用户画像的?
长安十二时辰的大案牍术是如何做用户画像的?
一部被称为“西安24小时”的古装剧《长安十二时辰》突然火了起来,在吸引了一堆粉丝之前,竟然先吸引了一批考据癖和技术控。
剧中有一个从未现身的角色,在推进剧情方面,竟然比主角都重要,它就是神秘的“大案牍术”。

原著第二章中作者曾这样介绍过男主人公张小敬:“他做不良帅那么多年,破案无数,深知很多事情并不需要搜考秘闻,真相就藏在人人可见的文卷之中,就看你能不能找出来,此所谓‘大案牍’之术。” 那么《长安十二时辰》破案中大行其道的“大案牍术”,究竟是何许物也呢?

“大案牍术”即指通过整理、归档、分析于公衙中的大量案牍,从而获得所需要的信息。换而言之,“大案牍术”即为唐朝版的大数据。我们从剧中可以看到“大案牍术”在大数据核心应用 “用户画像”这一场景的各种应用。
什么是用户画像?我们借用大数据中的概念,来介绍“大案牍术”中所使用的用户画像。
用户画像(persona)的概念最早由交互设计之父Alan Cooper提出:Personas are a concrete representation of target users. 它是指真实用户的虚拟代表,是建立在一系列属性数据之上的目标用户模型。(源自网络)

靖安司存储的万卷机要文件均是中文文档,从这些文档中提取有效信息发现长安民众、案件等实体关联性,需要使用NLP(自然语言处理)技术对语言文件解构,再利用知识图谱技术的图数据形式存储信息,描述客观世界中概念、实体及其关系。

所以,人形CPU徐宾,同时存储了长安知识图谱及各实体画像信息,要找到目标人物,只需将几行code输入大脑,瞬时分析出结果(张小敬和崔六郎),准确高效。
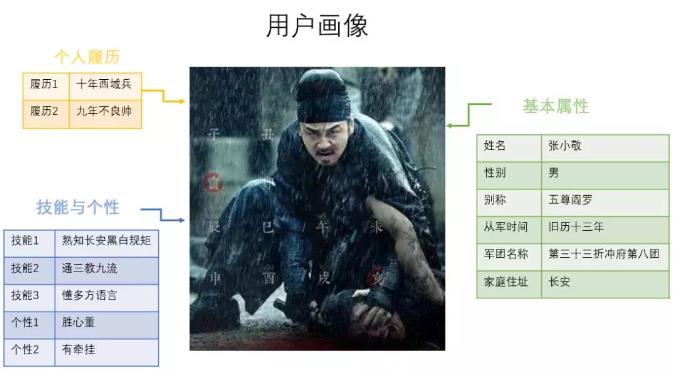
图中这一系列‘短文本’标签,是不是能够让你想象出一幅具体画面?联想到这位唐朝不良帅的尊容了呢?这就是用户画像的典型案例,其概念简单来说,就是‘大案牍’信息提取出的数据集合。
“大案牍术”由数据和算法两部分够成,数据包含靖安司收集到的百姓个人信息、军役信息、住宅信息等多维度信息,结合‘术数’算法,构建了用户画像数据库,用于绘制目标对象的全貌。而现在的大数据分析法则是企业将收集到的用户个人信息、订单信息、爬虫信息、埋点信息等进行挖掘分析,抽象出一系列低交叉率的短文本标签绘制一个用户商业全貌。

古代的‘大数据’来源于大量纸张记录的案件,但由于唐朝藤纸的匮乏,只有革新造纸术才能提高纸张生产力;当代大数据的量级远不是纸张能够满足的,这依赖于存储技术及计算技术的革新。《长安十二时辰》能够将‘大数据’用户画像技术提前上千年到唐朝,真是创意满满。
知己知彼,利人利己,唐朝大数据用户画像让靖安司迅速定位可用之人张小敬,最后关头阻止了上元节危机,解救长安城的黎民百姓;现代大数据用户画像不仅可以节省企业营销成本、提高盈利,且能够减少用户被打扰频率,节省用户购物时间,提升使用体验。

剧中靖安司相当于现代IT行业的大数据部门,不仅存储了三省六部、一台九寺五监24个国家重要机构的机密要件,并且招募了众位擅长记忆与思考的工程师(如徐宾),该部门的‘大案牍术’除了用户画像外,还有以下几个业务:
(1)数据统计,在剧中可以看到大案牍术能够根据类目、货物进出量等信息,查询到所有的进出长安的各种类易燃物,进货量异常的店家。从各维度统计数据量,用于分析变动情况,快捷有效地发现问题。
(2)数据分析,可以通过“大案牍术”查询假借住宅出租合约、通过长安县一年内户籍变动等资料,缩小可疑住址范围,尝试潜入京城的狼卫暂住地。数据分析的归纳、对比等方法,为观测用户行为变化情况提供了可能。
(3)数据建模,剧中旅贲军崔器谎报全奸狼卫,伪造尸首,靖安司行大案牍术,测量身高拆穿谎言。大数据的难点不在于数据量缺乏,而是准确度。只有保证数据准确度,才能建立有效模型用于分类与预测。
大案牍术虽然是完全虚构的,但大数据在我们身边的应用已经无处不在,在社会各个层面起着重要作用。
本文来自微信公众号“上海科技创新资源数据中心”。如需转载,请在“上海科技创新资源数据中心”后台回复“转载”
标签:
















